
ViewRAG 是一个专注于 PDF 智能解析与图文并茂问答 的 RAG (Retrieval-Augmented Generation) 系统。
项目的核心价值在于打破传统 RAG 仅限文本的局限,借助大模型(LLM)的深度理解能力,实现对文档中图片和表格的精准召回。通过结合 MinIO 对象存储与精心设计的 Prompt,系统能够引导 LLM 在回复中引用图片,避免长图片 URL 带来的困扰。同时,系统将参考来源同步传回前端,实现实时图片渲染与严格的PDF引用溯源,有效解决大模型回答的信任问题。

核心亮点
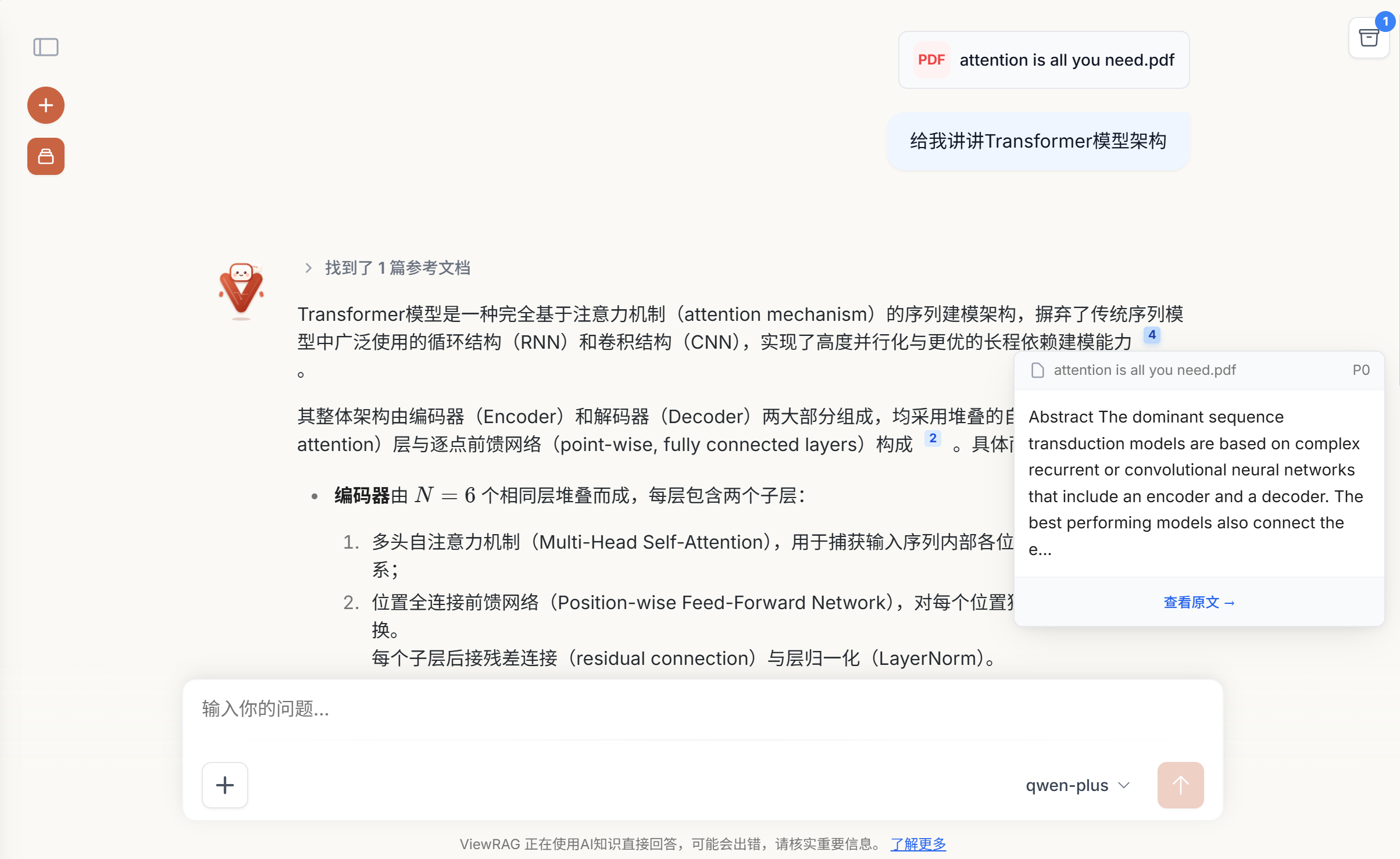
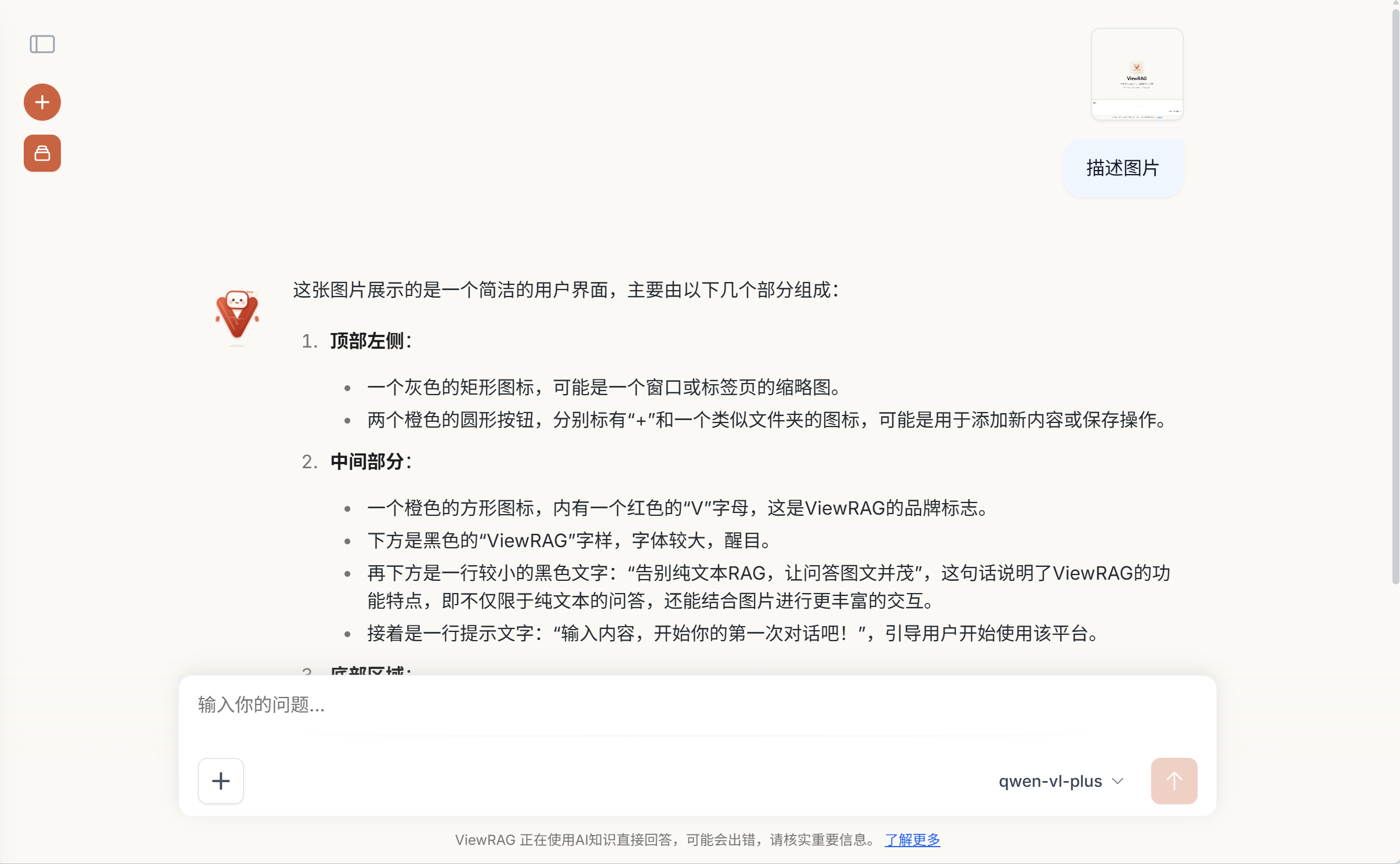
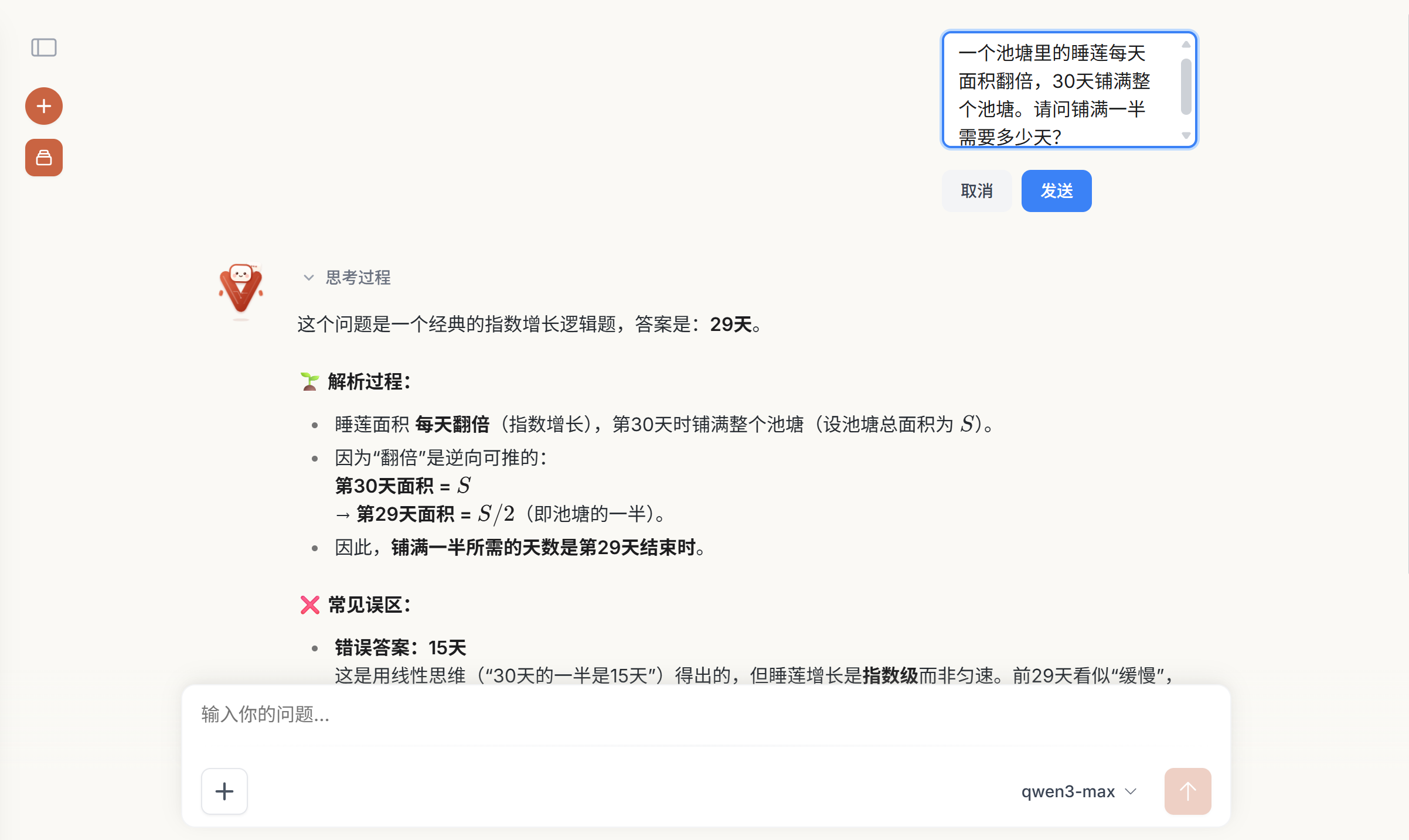
- 图文并茂的问答体验:LLM 回答时可内联引用图片,前端实时渲染展示,提供如同阅读原生文档般的丰富体验。
- 精准的引用溯源:回答自动附带引用编号,前端展示对应的文档页码、片段与图片预览,点击即可在内嵌 PDF 中高亮定位,解决 LLM 信任问题。
- 基于版式识别的智能分块:摒弃破坏信息连续性的传统固定长度/递归分块。充分利用 PDF 解析结果,保留原始段落结构,标题与正文自动合并,小块智能拼接(块大小 1024),兼顾语义完整性与检索精度。
- 图表深度理解:针对 PDF 中的图片和表格,调用视觉大模型和文本生成模型生成结构化语义描述,将其转化为向量用于后续召回,大幅提升图表内容的检索命中率。
- 全方位模型支持:支持灵活的模型选择与切换,全面兼容文本生成模型、多模态模型、深度思考模型。
- 极致的交互体验:支持从任意对话节点编辑问题并重新生成;文档处理全程 SSE 实时推送进度。
界面预览



核心功能
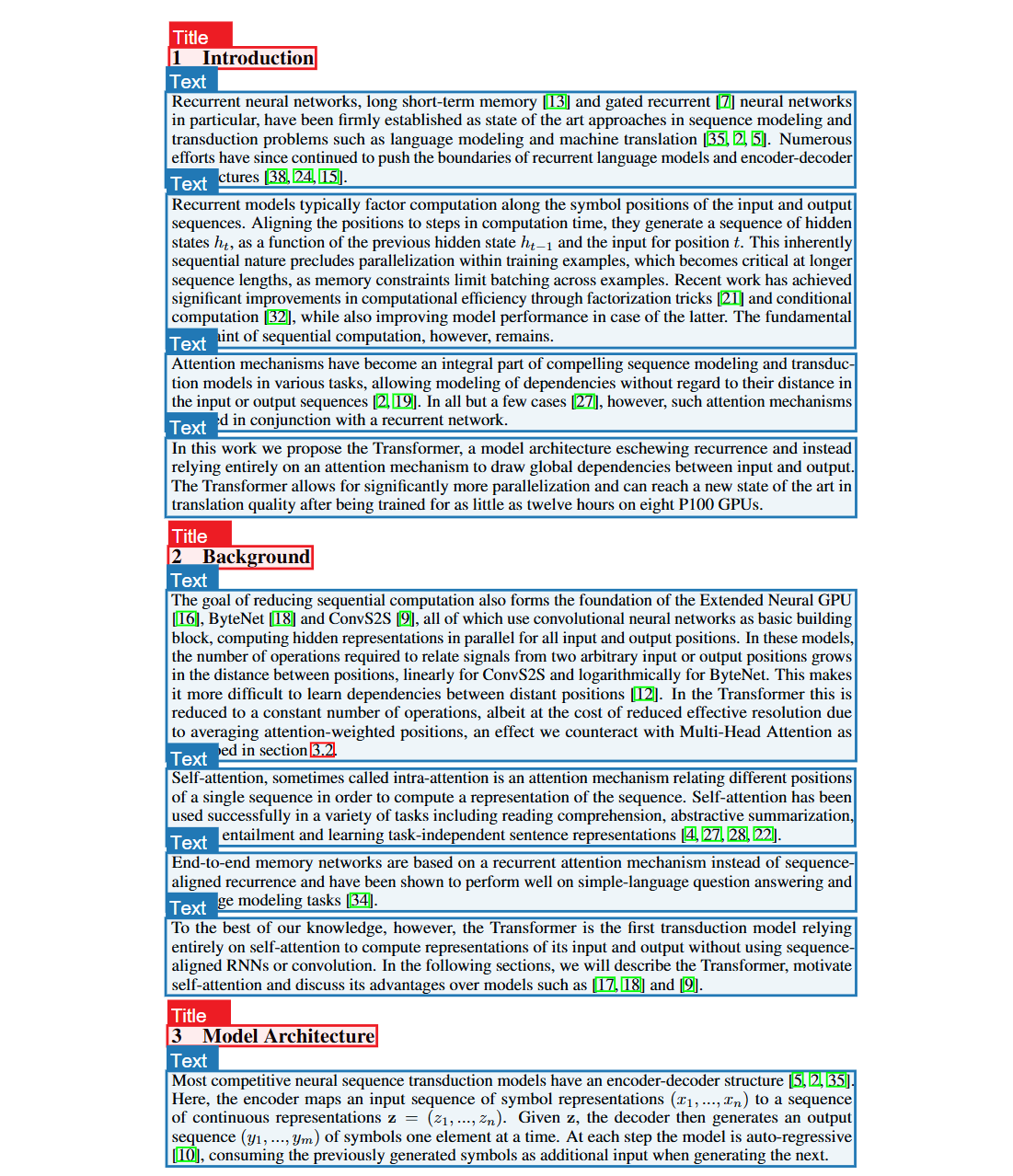
- 高质量 PDF 解析:对接 PaddleX 版式解析 API,识别文本、标题、图片、表格、公式等版面元素,并精准提取 bbox 坐标。
- 向量检索:基于 pgvector 的语义向量检索,支持按会话/知识库范围精确过滤。
- 问题重写:结合对话历史自动补全指代词,提升多轮对话下的检索准确率。
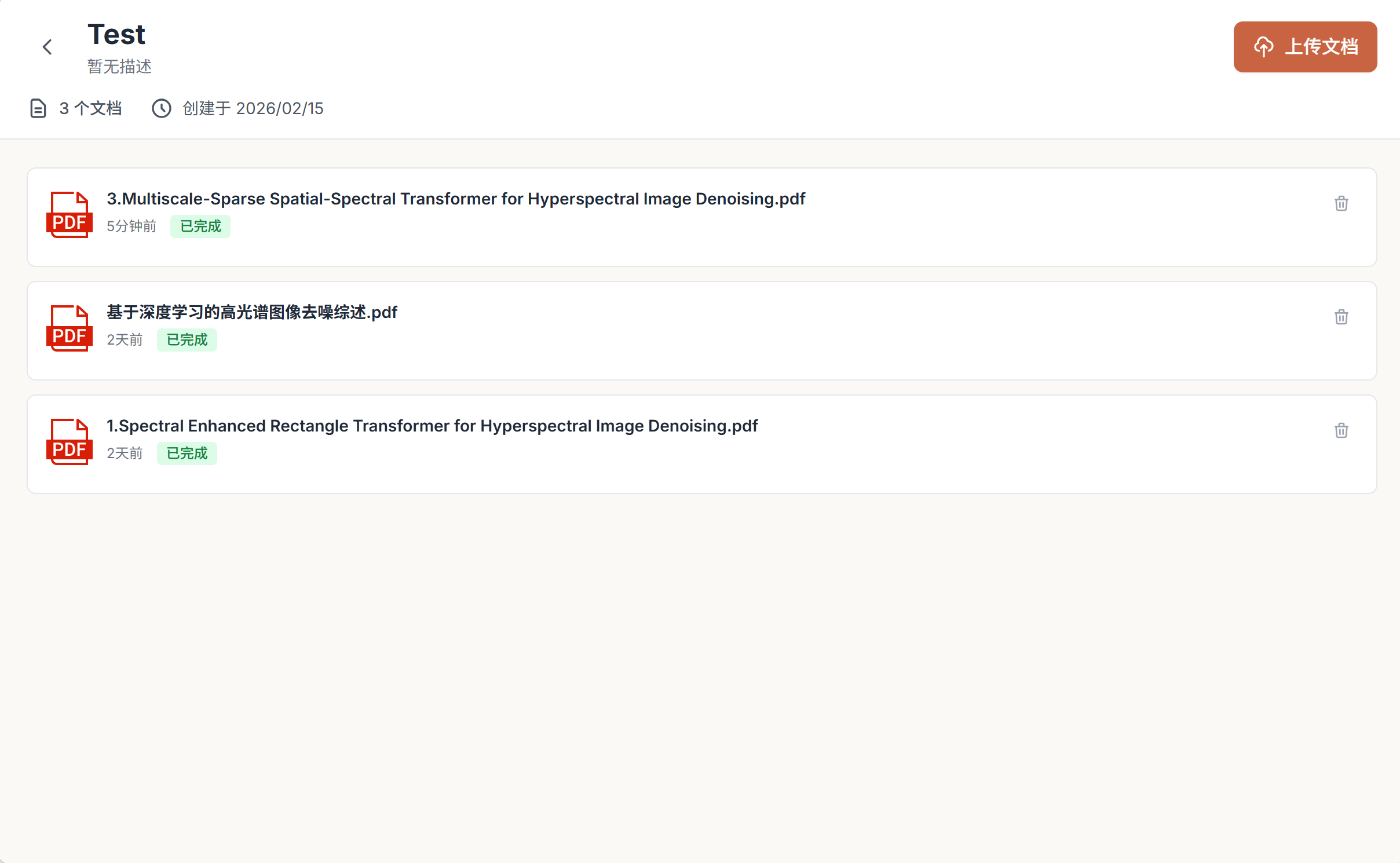
- 知识库管理:支持创建永久知识库,上传多份 PDF 统一检索。
- 会话文档:支持在对话中临时上传 PDF,仅在当前会话内检索。
- 多用户 / 多会话:独立账户体系,每用户独立会话与知识库。
- 兼容任意 LLM:所有模型均通过 OpenAI 兼容 API 接入,支持 Qwen、DeepSeek、GLM、Ollama 等。
系统架构
┌─────────────────────────────────────────────────────────┐
│ Nginx (8080) │
│ 反向代理 + SSE 无缓冲 + 大文件上传 │
└────────────────┬──────────────────┬─────────────────────┘
│ │
┌────────▼──────┐ ┌───────▼────────┐
│ Frontend │ │ Backend │
│ Vue3 + Vite │ │ FastAPI │
│ Nginx 静态 │ │ Python 3.10 │
└───────────────┘ └───────┬─────────
│
─────────────────────┼──────────────────────┐
│ │ │
┌────────▼────────┐ ┌─────────▼──────┐ ┌───────────▼───────┐
│ PostgreSQL │ │ MinIO │ │ PaddleX API │
│ + pgvector │ │ 文件 / 图片 │ │ PDF 版式解析 │
│ 向量 + 元数据 │ │ 对象存储 │ │ (外部服务) │
└─────────────────┘ └──────────────── └───────────────────┘PDF 处理流水线:
上传 PDF
→ PaddleX API 版式解析(识别文本/图片/表格/公式块)
→ PyMuPDF 按 bbox 裁剪图片 → 上传 MinIO
→ Block Chunker 分块(文本合并 / 图表独立)
→ Vision LLM 图片描述 / LLM 表格摘要(知识库模式)
→ Embedding 向量化 → 存入 pgvectorRAG 检索流水线:
用户提问
→ QueryRewrite 问题重写
→ Embedding 向量化查询
→ pgvector 相似度检索(按 kb_id / session_id 过滤)
→ ContextBuilder 构建上下文 + 分配引用编号
→ REFERENCE_SYSTEM_PROMPT 注入引用规则
→ LLM 流式生成(SSE 推送)
→ 前端解析 image:图片N 渲染图片 + [N] 渲染角标快速部署
环境要求
- Docker ≥ 20.10
- Docker Compose ≥ v2.0
1. 克隆项目
git clone https://github.com/David-Lolly/ViewRAG.git
cd ViewRAG2. 启动服务
cd docker
docker compose build
docker compose up -d首次运行会自动构建镜像,等待约 3~5 分钟。
3. 访问应用
http://localhost:80804. 完成模型配置
首次登录后进入配置页面,可以选择提供商快速完成模型配置,也可以手动填写模型信息(均支持 OpenAI 兼容 API):
PaddleX API 获取:前往 AI Studio 获取 PaddleX 版式解析服务,将
api_url和api_token,填入配置页面。
配置完成后点击各项的连接测试按钮,全部通过后保存即可开始使用。
源码部署(开发者)
需要提前自行部署 PostgreSQL(含 pgvector 扩展)和 MinIO,并在 backend/.env 中填写连接信息。
部署PostgreSQL和Minio
cd database
docker compose up -d后端:
conda create -n viewrag python=3.10
conda activate viewrag
cd backend
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python main.py前端:
cd frontend
npm install
npm run dev项目结构
ViewRAG/
├── docker/ # Docker 部署配置
│ ├── mount # 容器挂载
│ ├── docker-compose.yaml # 服务编排(postgres + minio + backend + frontend + nginx)
│ └── .env.docker # 环境变量(数据库、MinIO 账号)
├── nginx.conf # Nginx 反向代理配置(含 SSE 无缓冲规则)
│
├── backend/ # FastAPI 后端
│ ├── main.py # 应用入口,路由注册
│ ├── config.yaml # 模型配置(LLM / Embedding / Rerank / OCR)
│ ├── routers/ # API 路由
│ │ ├── llm.py # 聊天发送、RAG 检索、流式输出
│ │ ├── documents.py # 文档处理 SSE、PDF 流式下载
│ │ ├── knowledge_base.py # 知识库 CRUD
│ │ └── ...
│ ├── services/
│ │ ├── OcrAndChunk/ # PDF 解析与分块核心模块
│ │ │ ├── paddle_ocr/ # PaddleX 解析器(client / converter / parser)
│ │ │ ├── chunk/ # 分块策略(block_chunker / recursive_chunker)
│ │ │ ├── image_extractor.py # PyMuPDF 图片裁剪 + MinIO 上传
│ │ │ └── factory.py # OCR 解析器工厂
│ │ ├── document/
│ │ │ ├── enhancement_service.py # LLM 图片描述 / 表格摘要
│ │ │ └── vector_service.py # Embedding 向量化
│ │ ├── chat/
│ │ │ ├── context_builder.py # 检索结果 → LLM 上下文 + 引用编号
│ │ │ ├── query_rewrite.py # 多轮对话问题重写
│ │ │ └── prompts.py # 引用规则系统提示词
│ │ ├── retrieval_service.py # 统一向量检索入口
│ │ ├── chat_service.py # 消息构建(多模态/文本)
│ │ └── llm_service.py # LLM 流式调用
│ ├── models/models.py # ORM 模型(User / Session / Document / Chunk)
│ └── crud/ # 数据库 CRUD
│
└── frontend/ # Vue 3 前端
├── src/views/ # 页面组件
│ ├── ChatView.vue # 主聊天页面
│ ├── KnowledgeBaseList.vue / KnowledgeBaseDetail.vue
│ ├── PDFViewerPage.vue # PDF 内嵌预览(PDF.js)
│ └── ConfigView.vue # 模型配置页面
└── src/components/ # 可复用组件
├── chat/ # 消息渲染(含图片引用、角标)
├── DocumentUpload.vue # 文档上传 + 实时进度
└── pdf/ # PDF 查看器组件后续计划
- 实现AgenticRAG,智能化检索
- 支持本地PDF解析,不依赖PaddleOCR API调用
- 开发OCR服务接口,为bisheng提供OCR解析服务
贡献
欢迎提交 Issue 和 Pull Request!